
UUID, ULID, CUID, sau nanoID?
Ce sunt toate astea care se termină cu ID și de ce avem nevoie de ele?

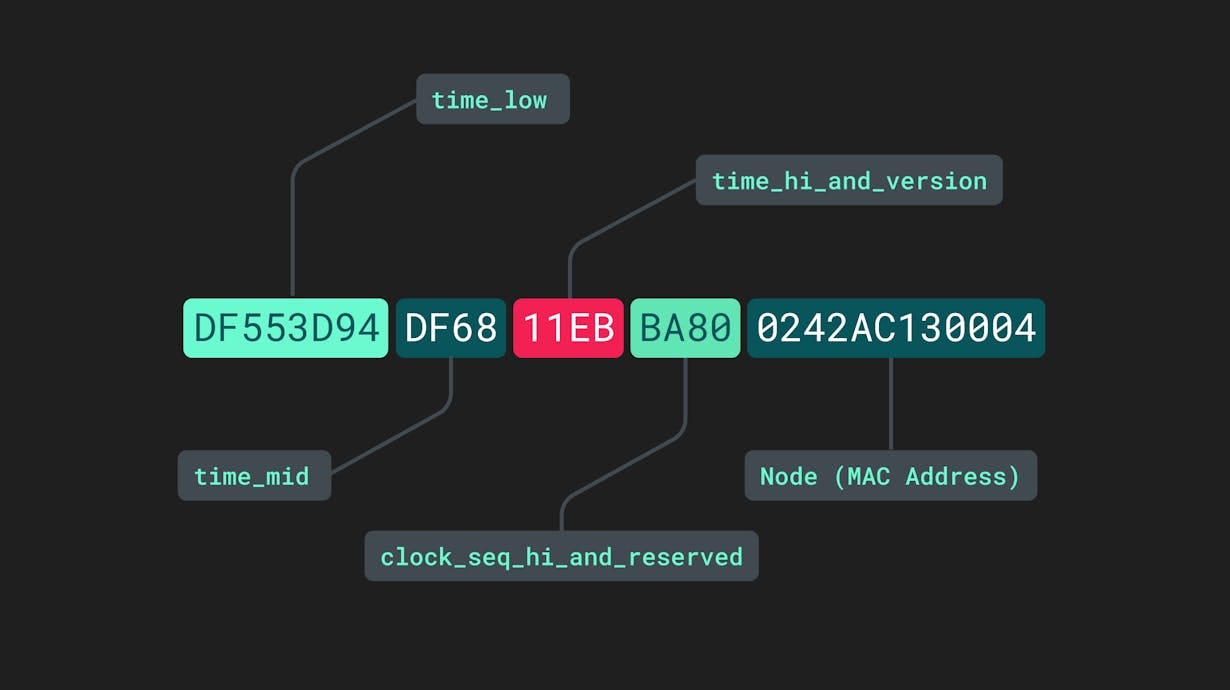
Știm cu toții de la cursul de baze de date și MySQL că orice rând ar trebui să fie identificat printr-un număr unic, respectiv un ID, care dacă este și index primar face accesarea acelui rând super rapidă. Dacă ați chiulit de la curs¸ nu-i bai, dar vă atenționez că acest articol este mai tehnic!
Ce-i un UUID?
Așadar, pe o bază de date relațională avem identificatori ca și chei primare pentru a accesa acele valori fără a penaliza performanța liniar cu adăugarea de rânduri noi. Care altfel, ar fi cel mai nefast scenariu pentru o bază de date!
Indecșii clasici, sunt de obicei numere pozitive (unsigned int sau bigint), tipuri destul de mari pentru a permite valori de ordinul miliardelor, și deci a susține un număr foarte mare de înregistrări. Însă aceste valori se repetă de la tabel la tabel, avem indecșii 49, 50 și 51 pe tabela users și 49, 50 și 51 și pe tabela admin_users. ID-ul 21 poate aparține la doi utilizatri, unul fiind admin.
Apoi, acești indecși sunt secvențiali: 1, 2, 4, 6, 7, 9; și nu se pot genera valori dacă sistemele nu sunt conectate cu baza de date pentru a accesa secvența precedentă, deci nu oferă toleranță la partiționare. Așa s-a născut conceptul de UUID - Universally Unique ID.
Aceste valori sunt stocate în binar sau ca șiruri de caractere, și sunt generate cu scopul de a identifica o întregistrare unică pe unul sau mai multe seturi de date.
Scenarii în care apelăm la UUID-uri
De cele mai multe ori uuid-urile sunt folosite pentru a oferi referințe între sisteme care fie sunt decuplate sau ne dorim să poată funcționa independent unul de altul.
Un frontend poate genera UUID-uri
Cel mai mare avantaj al UUID-urilor este că pot genera unul fără a cunoaște secvența precedentă, stocată pe tabela de date. În cazul MySQL de exemplu funcția mysql_insert_id este folosită pentru a determina ultima valoare secvențială, înainte de a insera un rând nou, dar pentru asta e nevoie să fim conectați la serverul MySQL. Spre deosebire, un UUID, poate fi generat din cod, chiar dacă aplicația nu este conectată la server. Și de exemplu pot genera și afișa un URL pentru o imagine care urmează să fie prelucrată de server, înainte ca imaginea să fie efectiv încărcată.
Collecții de date fault-tolerant
Un alt scenariu este acela în care am mai multe aplicații, și toate vor stoca date într-o colecție distribuită pe mai multe mașini sau noduri, pentru a prioritiza salvarea datelor, indiferent dacă unul sau mai multe noduri sunt offline.
Prevenirea de race-conditions și partiționare
Uneori avem nevoie de să putem stoca date într-un ritm susținut și cu latențe foarte mici. De exemplu mesajele de log generate de o aplicație sau tranzacții monetare care este imperativ să fie stocate chiar dacă înregistrarea este duplicată sau incompletă.
Standardul oficial UUID și copii lui
RFC 95621 este specificația de facto pentru sistemele și librăriile care generează identificatori globali unici. Sunt mai multe versiuni în această specificație. Din păcate unele versiuni nu sunt compatibile între ele. Iar versiunea 2 este de evitat. Cea mai populară și mai stabilă versiune este UUIDv4, și este cea recomandată la vremea acestui articol.

Dincolo de standard
Pe lângă RFC, sunt și alte specificații pentru UUID-uri. Desigur scopul unui generator este de a reduce coliziunile, dar în funcție de nevoile aplicației se poate folosi un generator care admite o rată de coliziuni, oferind în schimb viteză, suport pentru odronare sau variante mai scurte și mai rapid de transmis.
ULID2: este o alternativă care generează uuid-uri care sunt url-safe, fără caractere speciale și sortabile. Singura limitare este că se pot genera maxim 280 versiuni pe millisecondă.
NanoID3: ca și ulid, generează șiruri url-safe, oferind viteză sporită de generare. Permite configurarea lungimii, cu riscul de a avea o șansă mai mare de coliziuni, însă șirurile generate nu oferă suport pentru ordonare.
TypeID4: îmbină sportul pentru ordonare cu un prefix, care indică tipul sau entitatea referențiată.
Alte versiuni notabile: CUID, Snowflake ID, sqids.
UUID ca și cheie primară
Răspunsul scurt este NU, adică evitați folosirea de UUID-uri ca și chei primare. Deși tentația e mare și cu siguranță veți găsi pe web surse care declără că versiunea lor este bună pentru chei primare. Dar pe măsură de setul de date crește, accesul și inserția va fi îngreunată deoarece baza de date nu poate indexa și balansa eficient în lipsa unor chei implicit sortabile. Totuși țin să mențiionez că asta este specific bazelor de date relaționale (*SQL) care aplică indexare prin algoritmi binary tree sau B-Tree. În cazul bazelor de date NoSQL, indexarea se face prin algoritmi de hashing și aici cheile primare sunt UUID-uri.
Așadar, răspunsul mai lung este în funcție de sistemul de baze de date folosit de aplicație, dar puteți oricând folosi UUID-uri ca și chei secundare.